K-Means Clustering
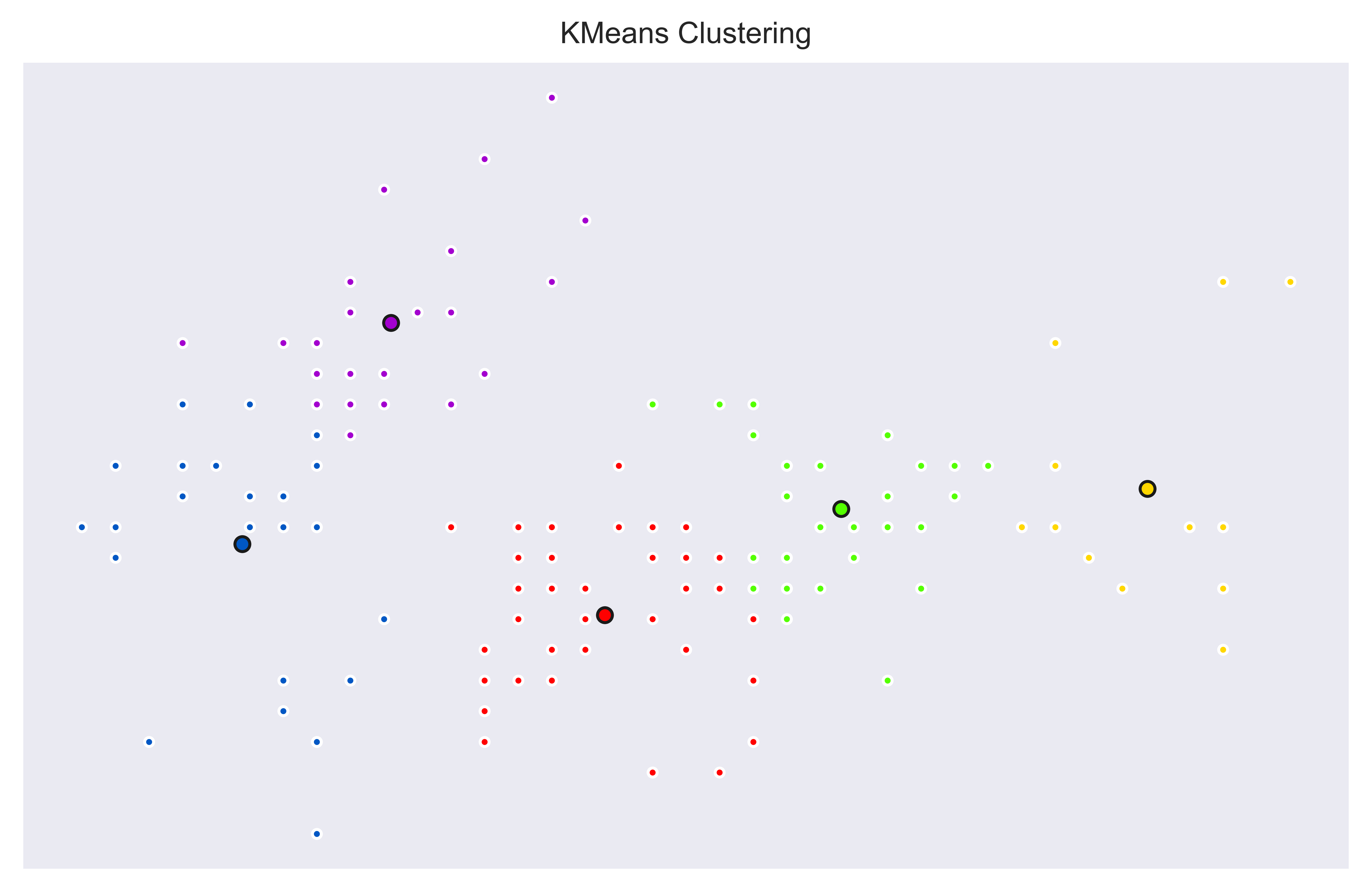
KMeans can be used for clustering unlabeled datasets and it performs quite well for clustering data into spherical separate shapes.
In this tutorial we will look at KMeans class and how it can be utilized using Scikit-learn library’s sklearn.cluster module.
How to Construct?
KMeans Model
You can import DecisionTreeClassifier from sklearn.tree module as below and use it to create a Decision Tree model object.
Creating KMeans Model:
from sklearn.cluster import KMeans
KM = KMeans()
Once the model is created next steps will be to fit the model and it will be ready for prediction.
Training KMeans Model:
There is not training phase for K-Means clustering algorithm. So, when we apply fit method K-Means will do all the clustering.
Clustering with KMeans Model:
KM.fit(X)
K-Means implementations are usually quite straightforward but if you are interested in optimization of KMeans Model’s hyperparameters, you can see the article below:
Characteristics of Suitable Data that can be used in K-Means Models
You can directly apply fit method to the KMeans model you’ve created with and provide the data to the model as well with the fit method.
There are a few points that should be noted regarding data involved in clustering with KMeans model:
- Scaling: K-Means is very sensitive to scaling of data. If columns have different scales they should be scaled so there isn’t bias when K-Means model is working.
- No labels: K-Means doesn’t need feature labels so even if there are label they should be excluded.
- Numerical Data Only: Categorical data cannot be used with K-Means clustering since distance calculations are a crucial part of the algorithm.
- Continous Data Only: K-Means also won’t function properly if numerical data is not continuous. In other words categorical data in numerical format still won’t be a good idea.
You can think of data used in K-Means like the X_train partition we normally use in Classification or Regression. Except there is no need for labels (usually column headers) and there is also no need for train / test split so the whole dataset can be used (except target values).
KMeans Summary
We have seen a simple introduction to the K-Means implementation in Scikit-Learn library of Python named KMeans. We have seen how it can be imported from sklearn.cluster module and further how it can be used to create an instance of KMeans class to create a model to be used in clustering.
We have also discussed how K-Means doesn’t require training and what kind of data is most suitable for clustering with K-Means algorithm.
For an example machine learning implementation as well as cluster visualization you can check out this example we have created with K-Means algorithm: